
Reading Tiff Tags 🏷
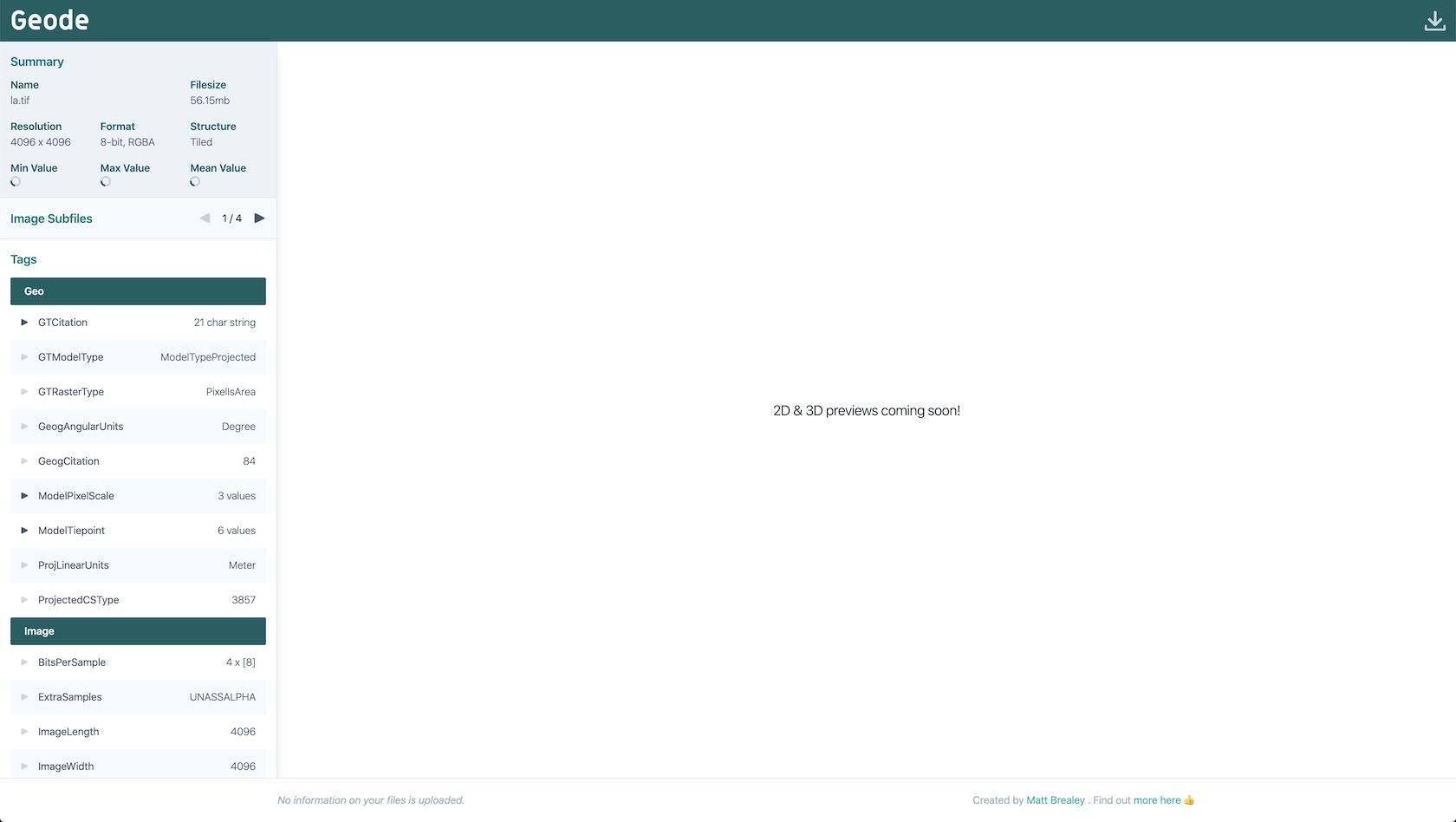
I’m currently in the process of adding several other formats to Areo, my ‘take binary elevation data and make into exportable 3D mesh’ tool, one of which is Geotiff. Instead of just figuring out how to read the format (boo, boring, boo), I thought I’d try and make an in-browser tool to read local tiff files, show 2D previews with custom colour mapping, and generate downloadable 3D mesh previews if applicable (hooray, 3D things, yay!) I also thought I’d briefly write it all up as I went. 👋
Incredibly useful sources of information
- This article by Patrick Armstrong really quickly got me up to speed on exactly how the header information in a .tiff file is formatted. Patrick also delves into things like compression, that I’ll definitely have to address down the line.
- Want to know what that random tiff tag ID is? Want to know all the possible values in its enum? Well Joris Van Damme from Aware Systems has you covered! This site is basically a tiff tag bible. It was insanely useful.
- As was Maptools.org! Many of my Google searches brought me back to the fantastically curated information on this site.
- Paul Bourke’s PDF Tiff Summary was also SUPER useful in clarifying the different data types used in the format.
- Finally, I stumbled upon Emily Selwood’s fantastic Tiff Hax tool as I was getting into the nitty gritty of IFD reading, and although I’ve yet to delve into Go, it was a fantastically useful sanity checker when it came to testing my own code!
Breaking down the format
Byte Order & A Very Magic Number
At the start of every .tiff file there are 8 bytes of data. Something like :
4D4D002A 00000008The first 2 bytes are either going to be both 4D (i.e. 77 as a UInt8), or 49 (i.e. 73 as a UInt8). If it’s 4D (77) the byte order of the file is BigEndian, if it’s 49 (73) byte order is LittleEndian. The example above is therefore BigEndian.
The 3rd or 4th byte (depending on your newly found byte order) is a magic number. Long story short, if it’s not 42, then this isn’t a tiff file. Time to return/throw an error/walk away and grab lunch.
The final 4 bytes, converted to a long (i.e. 4 byte, 32-bit unsigned int), gives us an offset to where the first main section of header information begins. Which leads me nicely into…
IFDs, subfiles, image bands…
A single tiff file can hold multiple different (but more often than not, at least tangentially related) images within it. These subfiles can be incredibly useful for storing lower resolution proxies of a main image, mask data, overlay information - essentially anything you want to bundle alongside the main image data.
Each one of these subfiles is described by an Image File Directory (IFD) - a section of header information containing all the metadata associated with that subfile. In theory. In practice, some of the tags on the first IFD are usually relevant to one or more of the subsequent IFDs, and as you delve deeper you might find other completely separate IFDs that contain yet more metadata relevant to the first IFD. Tiffs are nothing if not flexible.
If we follow the 8 byte offset we found above, we find ourselves at the start of our first IFD, which begins with these two bytes :
0010This is our IFD field count, which after converting to UInt8 tells us that there are 16 fields we now need to find and parse.
Fields. Oh so many fields…
IFD fields are always 12 bytes long, so let’s grab the next 12 bytes and start parsing :
01000003 00000001 0C890000The first 2 bytes give us the ID of the tiff tag. Converting 0100 to a short (AKA a 16-bit unsigned int) gives us a value of 256. One search of AwareSystems Tiff Tag Reference later and :

We’ve found an ImageWidth tag! Let’s move on and try to get the width itself.
The 3rd and 4th bytes give us the data type of this tag. Converting to a short, our 0003 gives a value of 3, meaning that the image width is also going to be a short.
The next 4 bytes give us the value count for the current field as a 32-bit unsigned int. In our case above, the 00000001 tells us that (logically) ImageWidth only has a single value.
The behaviour of the remaining 4 bytes differs slightly from field to field, depending on the data the field represents. For some fields with a single (often numerical) associated value, all of that value data can be found directly within the field bytes. However, in fields representing more complex values (such as arrays of information, longer strings etc.) the remaining bytes simply act as an offset to where that information is stored in the main body of the tiff file.
To determine whether the final bytes represent an offset, we can perform a simple calculation :
(# of values) * (# of bytes per value) > (# of bytes remaining)We know that we only have 4 bytes left from our original 12 bytes of field data, we’ve already calculated our value count, and we know that the data type is short (i.e. 2 bytes per value). So in the case of our ImageWidth field, this calculation becomes :
isOffset = (1 * 2) > 4This evaluates to false in our ImageWidth case, meaning that the final 4 bytes represent the actual value of the field. These bytes are 0C890000, which we can now convert to a value of 3209. We’ve found the width of our tiff file!
If isOffset had resolved to true, we’d then have to perform a subsequent lookup into the tiff file, using the value of the final 4 bytes as our offset, and (# of values) * (# of bytes per value) as our byte count.
The next IFD…
16 fields of 12 bytes later, there are 8 more useful bytes that make up this current IFD. Converted to a long these bytes give you the byte offset to the next IFD contained within the tiff file.
If this byte offset is > 0, you’ll need to loop around and repeat all of your field parsing on this new IFD. If this is the final IFD in the file, the byte offset will be 0, and you can now relatively comfortably stop processing IFDs. Hooray!
So far, so good
So ends this first, pretty dry article about Geode! Fun, eh? 😬 I’m hoping that the above might prove vaguely useful to anyone thinking about attempting something similar. And if not, it will at least remind me how I approached it, when I no-doubt find myself doing this again in a year or so!
If you head over to the app right now, you’ll be able to see the above in practice, as you can load any tiff file and browse all of the available tag information for each IFD found.
Next step, pixel loading!